پیام سپاهان - زومیت / ظاهراً عملکرد مدل هوش مصنوعی o3 در معیار FrontierMath، با آنچه OpenAI رسماً اعلام کرده بود، تفاوت زیادی دارد.
مدل هوش مصنوعی o3 که در دسامبر (آذر و دی 1403) معرفی شد، ابتدا با ادعای پاسخگویی به بیش از 25 درصد از سؤالات مجموعهی ریاضی FrontierMath توجهات را به خود جلب کرد؛ عددی که بهمراتب بالاتر از عملکرد سایر مدلها بود؛ اما حالا نتایج ارزیابی مستقل مؤسسهی Epoch AI، این ادعاها را زیر سؤال برده است.
طبق گزارش Epoch، مدل o3 فقط حدود 10 درصد از سؤالات FrontierMath را با موفقیت پاسخ داده که این عدد بسیار پایینتر از ادعای اولیهی OpenAI است.
همین اختلاف باعث شد بحثهایی دربارهی شفافیت و نحوهی بنچمارکگرفتن OpenAI شکل بگیرد، بهویژه اینکه نسخهی تستشدهی این شرکت احتمالاً به منابع پردازشی بیشتری دسترسی داشته است.
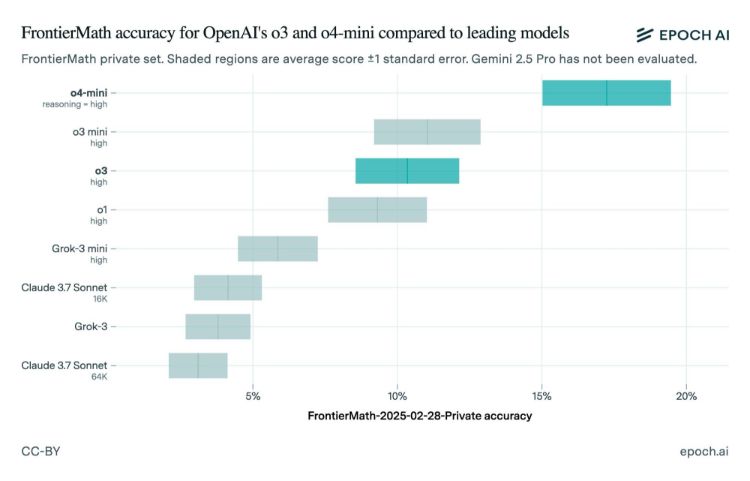
Epoch AI
بازار
![]()
بنیاد ARC Prize اعلام کرد که نسخهی عمومی مدل o3 با نسخهی مورد استفاده در بنچمارکهای اولیه تفاوت دارد و برای کاربردهای روزمره مانند چت بهینهسازی شده است. به عبارتی، نسخهی نهایی عملکرد بهتری در دنیای واقعی دارد، اما در تستهای سنگین امتیاز کمتری کسب میکند.
شرکت OpenAI نیز اذعان داشت که نسخهی نهایی o3 بهمنظور افزایش سرعت پاسخدهی و کاهش هزینه بهینه شده است و امکان دارد با نسخهی نمایشی اولیه در نتایج بنچمارک تفاوتهایی داشته باشد. این شرکت همچنین وعده داد در آیندهی نزدیک مدل قدرتمندتری تحت عنوان o3-pro منتشر خواهد شد.
ماجرای نتایج عملکرد مدل o3 بار دیگر نشان میدهد که بنچمارکهای مدلهای هوش مصنوعی همیشه قابل اتکا نیستند؛ بهویژه زمانی که از سوی شرکتهای سازندهی مدلها منتشر شوند. در شرایط رقابتی فعلی بازار هوش مصنوعی، شرکتها گاهی برای جلب توجه، اطلاعات خود را بهصورت گزینشی منتشر میکنند.
http://www.sepahannews.ir/fa/News/958828/مدل-هوش-مصنوعی-o3-شرکت-OpenAI-در-ارزیابیها-کمتر-از-انتظار-امتیاز-گرفت